Nowości
Anthropic ujawnia system klasyfikacji zagrożeń cybernetycznych dla Claude Fable 5
Posłuchaj tego artykułu
Anthropic opublikował szczegóły zabezpieczeń modelu Claude Fable 5 przed nadużyciami w cyberbezpieczeństwie oraz nową skalę oceny powagi jailbreaków, tworzoną wspólnie z Amazonem, Microsoftem i Google w ramach Project Glasswing.
Spis treści
Anthropic opisał, jak dokładnie broni swojego najnowszego modelu, Claude Fable 5, przed wykorzystaniem do ataków hakerskich, i zaproponował branżowy standard mierzenia, jak groźny jest dany jailbreak. To pierwsza tak szczegółowa publikacja tego typu w firmie, powstająca w momencie, gdy rządy coraz mocniej naciskają na kontrolę dostępu do najsilniejszych modeli AI.
Cztery poziomy ryzyka
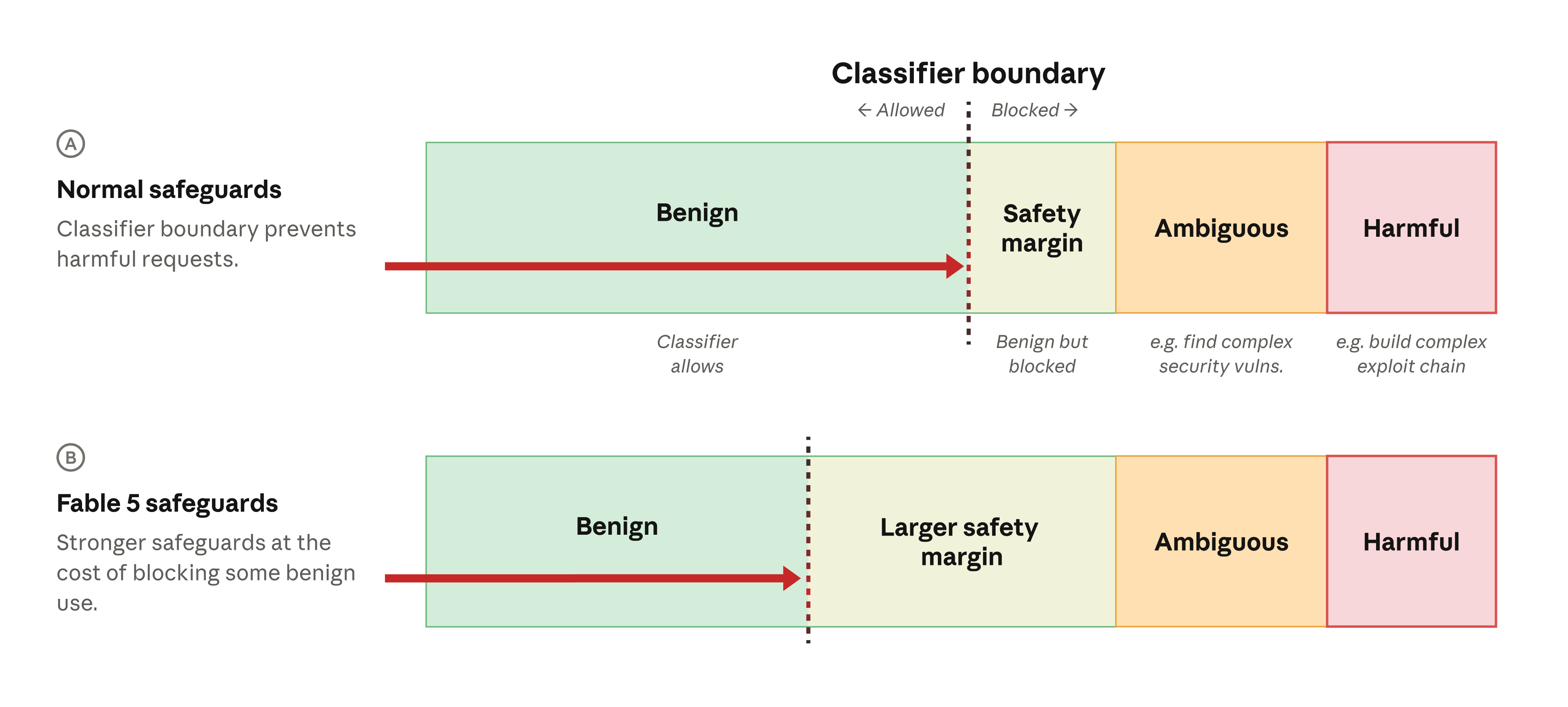
System klasyfikatorów w Fable 5 nie blokuje całej aktywności związanej z bezpieczeństwem, tylko dzieli zapytania na cztery kategorie. Najniższy poziom to działania zabronione całkowicie, jak tworzenie ransomware, wiperów, sabotaż cyberfizyczny czy infrastruktura command and control, bo ich potencjał szkody jest wysoki, a wartość obronna niska. Wyżej są zastosowania dual-use wysokiego ryzyka, czyli testy penetracyjne, tworzenie exploitów czy eskalacja uprawnień, blokowane do czasu lepszej weryfikacji uprawnień użytkownika.
Trzecia kategoria to dual-use niskiego ryzyka, monitorowane, ale czasem dopuszczane, a czwarta to zastosowania łagodne, jak bezpieczne programowanie, zarządzanie łatkami, analiza w centrach operacji bezpieczeństwa czy reagowanie na incydenty. Anthropic podkreśla, że margines bezpieczeństwa dla Fable 5 ustawiono wyżej niż dla innych modeli, co oznacza, że więcej niegroźnych zapytań może zostać zablokowanych kosztem wygody użytkownika.
Skala CJS krok po kroku
Nowa skala Cyber Jailbreak Severity ocenia, jak poważny jest dany sposób obejścia zabezpieczeń modelu. System liczy cztery wskaźniki, zysk zdolności w skali od 0 do 4, zasięg zastosowań od 0 do 2, łatwość uzbrojenia od 0 do 2 oraz wykrywalność od 0 do 2. Wyniki sumują się w jeden z pięciu poziomów, od CJS-0 przez informacyjny i niski, po średni, wysoki i krytyczny CJS-4.
Model działa według logiki logarytmicznej, więc każdy kolejny poziom oznacza znacznie poważniejsze zagrożenie niż poprzedni, a nie liniowy wzrost. Ostateczna ocena może zostać podniesiona na podstawie dodatkowych czynników uznaniowych, ale nigdy obniżona, co ma zapobiegać bagatelizowaniu realnych zagrożeń.
Wspólny język dla branży i rządów
Anthropic pracuje nad frameworkiem razem z Amazonem, Microsoftem i Google w ramach Project Glasswing. Firma opisuje to jako wczesny etap budowania wspólnego słownictwa między twórcami AI a rządami, tak by rozmowa o ryzyku jailbreaków wyglądała podobnie niezależnie od tego, który laboratorium raportuje incydent. Uwagi do propozycji można zgłaszać na adres cyber-safeguards@anthropic.com.
Współpracując razem, możemy ustanowić standard, który umożliwia obronne zastosowania tej technologii, jednocześnie zapobiegając jej nadużyciom - Anthropic
Firma uruchomiła też dedykowany program na platformie HackerOne, gdzie badacze bezpieczeństwa mogą zgłaszać odkryte w Fable 5 metody obchodzenia zabezpieczeń do przeglądu przez zespół Anthropic. To rozszerza wcześniejsze doświadczenia firmy z modelem Mythos, do którego dostęp był ograniczany ze względu na ryzyko nadużyć w obszarze cyberbezpieczeństwa.
Kontekst regulacyjny
Publikacja pojawia się kilka dni po tym, jak Departament Handlu USA zniósł czasowe ograniczenia eksportowe na Fable 5, nałożone wcześniej po wykryciu luki bezpieczeństwa w modelu. Fable 5 wrócił do wszystkich użytkowników na świecie 1 lipca 2026 roku. Rządowa kontrola nad dostępem do najsilniejszych modeli AI rośnie w USA równolegle z rozwojem takich mechanizmów samoregulacji przemysłu.
Dla firm korzystających z Claude w obszarze cyberbezpieczeństwa, w tym z polskich zespołów SOC czy działów red teamowych, oznacza to jaśniejsze reguły gry: legalne testy penetracyjne czy fuzzing pozostają dostępne po weryfikacji kontekstu, a granica między pracą obronną a ofensywną staje się przedmiotem jawnie opisanej polityki, a nie czarnej skrzynki klasyfikatora.
Skala CJS, jeśli zostanie przyjęta szerzej przez inne laboratoria, może stać się punktem odniesienia podobnym do skal CVSS znanych z klasycznego zarządzania podatnościami, tyle że dla ryzyk związanych z obchodzeniem zabezpieczeń modeli językowych. To ważne również dla instytucji regulacyjnych, które szukają wspólnego języka do oceny raportów o incydentach związanych z AI.
Źródła: More details on Fable 5's cyber safeguards and our jailbreak framework (anthropic.com), Anthropic Details Claude Fable 5 Cybersecurity Safeguards and Jailbreak Framework (cybersecuritynews.com)